트리시터를 활용해 네오빔 플러그인 개발하기
시작하기
최근에 트위터를 시작했다. 일론 머스크의 인수 여파로 분위기는 조금 어수선하지만, 개발 관련 소식을 빠르게 접할 수 있다는 장점은 그대로 남아있다.
지난주에는 우연히 이 트윗을 보는데,
간단하지만 아이디어가 기발해 따라 만들고 싶은 욕구가 샘솟았다. HTML(또는 JSX) 코드를 작성하다 보면 클래스 속성을 쓰고 지우는 일이 번거롭게 느껴지곤 하는데
justinrassier
는 트리시터를 활용해서 클래스 속성이 존재하면 가장 끝으로 커서를 옮겨주고, 없다면 새로 추가하는 방식으로 문제를 해결하고 있었다. 이 글은 내가 기능을 구현하며 배운 점과 느낀 점을 설명하는 글이다. 그럼 먼저 문제점과 해결 방안을 정리해보자.
문제점
-
클래스 이름을 추가하기 위해 커서를 옮기는 일은 번거롭다. 클래스 목록이 길어질수록 눌러야 하는 키의 개수도 늘어난다.
-
클래스 속성을 추가하는 일은 더욱 귀찮다. 먼저 커서를 원하는 위치로 옮긴 후,
class="..."를 입력해야 한다. 만약JSX나TSX를 사용 중이라면className을 사용해야 하는 탓에 입력할 문자 수가 늘어난다. -
클래스 속성을 지우는 일 또한 마찬가지로 귀찮다. 만약 문서의 최하단에서
<html>태그 내의 클래스 속성을 지우고 싶다면 문서 상단으로 이동해 지울 영역을 직접 선택해야 한다.
해결 방안
-
커서를 클래스 속성 끝으로 옮기고 입력모드로 전환하는 유틸 함수를 만든다 (위의 트윗에 나온 것과 동일한 기능). 이 함수는 동일한 문맥 안에서는 커서 위치에 구애받지 않고 같은 동작을 수행해야 한다. 예를 들어 한 요소의 시작 태그와 끝 태그에서 실행한 함수는 같은 결과를 낸다.
-
만약 클래스 속성이 존재하지 않는다면 새로운 속성을 추가해준다. 이때 커서 위의 언어가
JSX나TSX라면classname을 사용한다. -
클래스 속성을 자동으로 지워주는 유틸 함수를 만든다.
이제 위의 기능들을 어떻게 구현하는지, 그리고 트리시터는 어떻게 활용되는지 본격적으로 알아보도록 하자.
트리시터를 알아보자
트리시터 활용법을 얘기하기 전에 트리시터란 무엇인지 간단히 알아보자. 트리시터는 파서(parser) 제작 툴이자 점진적 파싱(incremental parsing)을 지원하는 라이브러리이다. 여기서 점진적 파싱이란, 문서가 변경될 때 전체 영역을 재분석할 필요 없이 변경된 부분만 분석하는 기능을 의미한다. 이 특징 덕에 트리시터는 다른 파싱 라이브러리보다 좀 더 효율적으로 구문을 분석할 수 있다.
네오빔은 0.5 버전부터 트리시터를 기본적으로 지원한다. 이는 기존 빔과 네오빔의 가장 큰 차이점 중 하난데, 좀 더 강력한 기능을 쉽게 구현할 수 있도록 도와주고 있다. 일례로 트리시터 도입 전의 구문 강조(syntax highlighting)와 들여쓰기(indentation)는 항상 까다로운 장애물처럼 여겨졌지만, 도입 후에는 몇 가지 설치과정을 거치면 누구나 쉽게 설정할 수 있게 되었다. 특히 여러 가지 언어가 섞인 (예: React, Astro) 언어 또는 프레임워크를 주로 사용하는 웹 개발자라면 트리시터 지원은 더욱 반가운 소식이다.
트리시터에 대하여 더 배우고 싶다면 공식 문서 를 먼저 훑어보는 것을 추천한다.
네오빔에서 트리시터 사용하기
먼저
nvim-treesitter
를 통해 언어별 파서를 설치한다. nvim-treesitter는 트리시터 파서를 쉽게 설치하고 관리하도록 도와주는 인터페이스와 모듈을 제공하는 필수 플러그인이다. 예를 들어 HTML 파서를 :TSInstall html과 같은 식으로 쉽게 설치가 가능하다.
추가로 빠른 트리시터 쿼리(query) 작성을 위해 nvim-treesitter/playground 를 설치한다. 이 플러그인은 말 그대로 쿼리를 바로 테스트 해 볼 수 있는 플레이그라운드 인터페이스를 제공한다.
필요한 파서를 다 설치했다면 이제 쿼리를 작성해보자.
트리시터 쿼리 기초
트리시터 설정을 마치고 파서가 지원되는 언어의 문서를 열면 트리시터는 곧바로 문서를 파싱해 구문 트리(syntax tree)를 만든다. 이제 쿼리를 작성함으로써 트리 내 원하는 노드에 접근하고 정보를 가져올 수 있게 된다.
특정 노드에 접근해 캡처(capture)하기 위해서는 괄호 안에 노드의 이름을 적고 @ 부호와 함께 이름을 부여해주면 된다.
((node) @my_node)좀 더 깊숙이 들어가 중첩된 노드를 선택하고 싶다면 부모 노드의 괄호 안에 또 다른 괄호로 감싼 노드 이름을 적으면 된다.
((node (nested_node) @my_nested_node))특정한 위치의 노드를 이름과 관계없이 모두 선택하려면 와일드카드 노드 (_)를 사용할 수 있다. 이 노드는 정규 표현식의 .과 비슷하게 동작한다.
(node (_) @nested_node)
# 또는
(node (_ (child_node)))마지막으로 대괄호([]) 안에 두 개 이상의 패턴을 넣어 일치하는 노드에 다른 이름을 부여하는 것도 가능하다. 이는 정규 표현식의 대괄호 매칭과 비슷하다.
(node [(this_node) @this (that_node) @that])이 밖에도 쿼리 작성에 쓰인 다른 문법은 아래에서 필요할 때 설명하도록 하고 이제 예시를 통해 구문트리를 알아보도록 하자.
(공식 문서의 Query Syntax 항목에 보다 자세한 설명이 있으니 관심이 있다면 더 읽어보는 것을 추천한다.)
HTML 구문 트리
위에서 설명한 nvim-treesitter/playground 플러그인을 설치하고 커맨드 모드에서 :TSPlaygroundToggle을 입력하면 구문 트리의 모습을 살펴볼 수 있다. 만약 오류가 일어난다면 HTML 파서가 제대로 설치되었나 체크해보자.
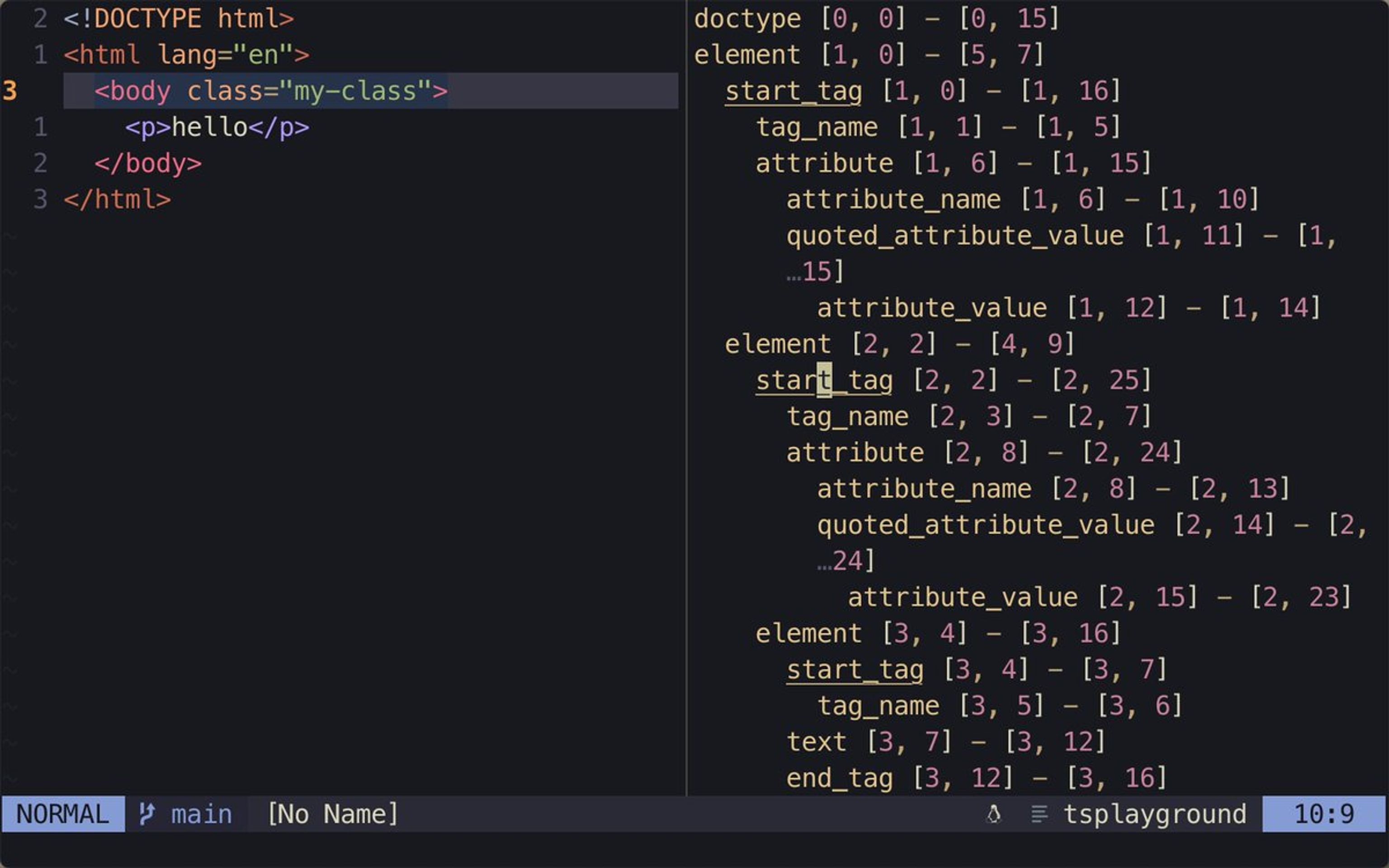
아래의 작은 HTML 문서는,
<!DOCTYPE html>
<html lang="en">
<body class="my-class">
<p>hello</p>
</body>
</html>이렇게 표현된다:
doctype [0, 0] - [0, 15]
element [1, 0] - [5, 7]
start_tag [1, 0] - [1, 16]
tag_name [1, 1] - [1, 5]
attribute [1, 6] - [1, 15]
attribute_name [1, 6] - [1, 10]
quoted_attribute_value [1, 11] - [1, 15]
attribute_value [1, 12] - [1, 14]
element [2, 2] - [4, 9]
start_tag [2, 2] - [2, 25]
tag_name [2, 3] - [2, 7]
attribute [2, 8] - [2, 24]
attribute_name [2, 8] - [2, 13]
quoted_attribute_value [2, 14] - [2, 24]
attribute_value [2, 15] - [2, 23]
element [3, 4] - [3, 16]
start_tag [3, 4] - [3, 7]
tag_name [3, 5] - [3, 6]
text [3, 7] - [3, 12]
end_tag [3, 12] - [3, 16]
tag_name [3, 14] - [3, 15]
end_tag [4, 2] - [4, 9]
tag_name [4, 4] - [4, 8]
end_tag [5, 0] - [5, 7]
tag_name [5, 2] - [5, 6]가장 먼저 HTML 요소를 의미하는 element 노드가 눈에 띈다. 그 아래의 start_tag는 HTML 요소의 시작 태그 노드이고, tag_name은 그 요소의 이름에 대응하는 노드이다. 태그 안에 정의된 속성은 attribute 노드와 자식 노드를 통해 접근이 가능하다.
플레이그라운드 안에서는 커서를 이동할 때마다 커서 위 노드에 매칭되는 HTML 요소를 하이라이트 해서 보여주기 때문에 더욱 직관적으로 확인해볼 수 있다. I를 누르면 노드와 관련된 파서 언어를 보여주고 o를 누르면 쿼리를 작성하고 바로 결과를 볼 수 있는 연습 공간이 생긴다.
클래스 속성값을 가져오는 쿼리 작성하기
HTML 요소는 크게 세 가지 경우로 나눌 수 있다.
- 클래스 속성이 없는 요소
- 값이 없는 클래스 속성을 가진 요소
- 한 개 이상의 값을 가진 클래스 속성이 포함된 요소
<p>첫 번째 케이스</p>
<p class="">두 번째 케이스</p>
<p class="my-class ...">세 번째 케이스</p>먼저 클래스 속성이 없는 요소인지 확인하려면 attribute_name 노드에 값이 있는지 없는지 알아본다. 또한 클래스 속성을 새로 추가할 때 tag_name 노드의 위치 정보가 필요하기 때문에 쿼리를 따로 작성해 저장해둔다.
((attribute_name) @attr_name)# HTML에는 두 종류의 시작 태그가 있다
([( start_tag ) ( self_closing_tag )] @tag)클래스 속성이 이미 있다면 attribute_name 바로 옆에 자리한 quoted_attribute_value 노드에서 값을 가져와야 한다.
하지만 단순히 quoted_attribute_value 노드를 캡처하면 클래스 속성뿐만 아니라 원하지 않은 src나 href 같은 속성까지 모두 선택된다. 그럼 어떻게 해야 클래스 노드만 캡처할 수 있을까?
술어(predicates)를 활용해 클래스 속성 골라내기
특정 조건에 만족하는 노드만 골라내기 위해서 트리시터의 술어(predicates) 문법을 사용해보자. 네오빔에서 지원하는 트리시터 술어 중 #eq?는 조건과 일치하는 노드를 찾을 때 쓰인다.
((attribute_name) @attr_name (#eq? @attr_name "class") (quoted_attribute_value) @attr_value)이 쿼리는 attribute_name 노드를 @attr_name이라는 이름으로 캡처하고 다시 캡처한 노드의 값이 class와 일치하는 노드만 골라낸다. 그리고 클래스 속성의 값이 들어있는 quoted_attribute_value 노드를 @attr_value라는 이름으로 가져온다.
이 밖에도 네오빔에서 지원하는 다른 술어가 궁금하다면 공식 문서 를 통해 확인해볼 수 있다.
캡처된 노드 탐색하기
필요한 쿼리를 모두 작성했다면 이제 캡처한 노드를 살펴볼 차례다. 이를 위해서는 parse_query 함수를 사용한다. parse_query 함수는 첫 번째 인자로 쿼리의 언어 정보를 받고 두 번째 인자로 쿼리를 받는다. 언어 정보는 문서의 ft 옵션을 통해 쉽게 알아낼 수 있다.
local filetype = vim.api.nvim_buf_get_option(0, "ft")
local lang = require("nvim-treesitter.parsers").ft_to_lang(filetype)
local query_text = [[ ... ]] -- 쿼리
local query = vim.treesitter.query.parse_query(lang, query_text)💡 팁
nvim-treesitter.parsers 모듈 안에는 filetype을 lang으로 변환해주는
ft_to_lang이라는 함수가 있다. 이 함수를 이용하면 JSX나 TSX를 사용할 때
생기는 예외적인 문제를 해결할 수 있다.
이제 parse_query 함수에서 반환된 쿼리 오브젝트와 iter_captures 함수를 가지고 원하는 노드를 탐색할 수 있다. iter_captures 함수는 총 네 개의 인자를 가진다. 탐색할 트리시터 노드, 버퍼(buffer) 번호, 그리고 탐색의 시작과 끝 행 정보를 넘겨주면 캡처된 노드와 아이디 번호, 그리고 그 밖의 정보를 담은 메타데이터(metadata)를 리턴한다.
-- for-loop pattern
for id, capture, metadata in query:iter_captures() do
-- ...
end💡 팁
캡처된 노드는 테이블 형태로 리턴되는데, 테이블의 내용을 출력하지 않는 루아의
print 함수로는 내용물을 확인해 볼 수가 없다. 다행히도 빔은 이를 위해 두
개의 함수를 제공한다. 사용법은 다음과 같다: print(vim.inspect(table)) 또는
vim.pretty_print(table). 두 번째 방법은 네오빔 0.7 이상 버전에서만
제공된다.
이제 준비는 다 되었다. 마지막으로 iter_captures 함수에 전달할 시작 노드만 찾으면 된다. 어떤 노드에서 시작하는 게 좋을까? 당연히 커서 위치에서 가장 가까운 노드부터 시작해야 한다.
네오빔에는 커서 위의 노드를 리턴해주는 get_node_at_cursor라는 함수가 있다. 하지만 이 함수는 노드를 문자열 형태로 리턴하는데, iter_captures에 전달할 노드는 tsnode 객체여야 한다. 내가 대신 사용할 함수는 nvim-treesitter.ts_utils 모듈 안의 get_node_at_cursor 함수다. 같은 이름이지만 이 함수는 tsnode 객체를 리턴한다.
local ts_utils = require("nvim-treesitter.ts_utils")
local node = ts_utils.get_node_at_cursor()하지만 만약 커서가 정확히 element 노드 위에 있는 게 아니라면 내가 리턴 받을 노드는 element 노드의 자식 또는 그보다 더 하위의 노드일 것이다. 내가 적은 쿼리는 시작 노드가 element 노드일 때만 제대로 동작하기 때문에 구문 트리를 타고 올라가 가장 가까운 element 노드를 찾아야 한다.
while node:type() ~= "element" do
-- `doctype` 노드 같은 예외 처리
if node:parent() == nil then
return
end
node = node:parent()
end이 방법으로 시작 노드가 항상 가장 가까운 element 노드라는 가정을 할 수 있다. 이제 이 노드를 iter_captures 함수에 넘겨주자.
-- 커서
local cursor = vim.api.nvim_win_get_cursor(0)
local cursor_row, cursor_col = unpack(cursor)
-- 커서가 위치한 줄만 탐색하기
for id, capture, metadata in query:iter_captures(node, bufnr, cursor_row - 1, cursor_row) do
-- 캡처된 노드의 시작과 끝 행 정보 알아내기
local capture_start_row, capture_start_col, capture_end_row, capture_end_col = capture:range()
local name = query.captures[id]
if name == "attr_value" then
vim.api.nvim_win_set_cursor(0, { capture_end_row + 1, capture_end_col })
-- insert 모드 시작
vim.cmd("startinsert")
-- 끝에 공백 추가
vim.api.nvim_feedkeys(" ", "n", false)
end
end캡처된 노드가 attr_value 노드일 경우, 커서를 클래스 속성값의 끝으로 옮기고 입력 모드로 바꾼다. 입력 모드 상태에서 " "를 입력한다.
요소가 두 줄 이상일 때는 어떡하지?
위의 코드는 요소가 한 줄일 때 아주 잘 동작한다. 하지만 두 줄 이상의 요소를 만나면 다른 문제점이 발생한다. 현재 코드는 커서가 올라간 줄 단 한 줄에서만 탐색을 하고 있다. 그래서 요소가 두 줄 이상이 되면 모든 영역을 탐색할 수 없게 된다. 또한 커서 위치를 새로 지정할 때 참고할 정보가 없는 상태이기 때문에 맞는 위치에 커서를 놓을 수가 없다.
사실 더 큰 문제는 요소의 닫는 태그(종료 태그)에서 함수를 호출했을 때 제대로 동작하지 않는다는 점인데, 이것도 역시 같은 이유로 발생하는 문제이다.
추가로 nvim_feedkeys 함수를 이용해서 공백을 추가하는 방법은 뭔가 안전한 방법이 아닌 것 같다. 이것도 함께 바꿔보자.
옵션 1: 더 완전한 쿼리 작성하기
더 완전한, 완벽한 쿼리를 작성할 수 있다면 커서가 있는 줄의 노드만 탐색해도 “맥락”을 파악할 수 있기 때문에 종료 태그 위에서도 정확한 동작이 가능해진다. 예를 들어서,
;; @tag_name 캡처
(element [(start_tag (tag_name) @tag_name) (self_closing_tag (tag_name) @tag_name)])
;; 클래스 속성을 @attr_value라는 이름으로 캡처
(element (_ (attribute (attribute_name) @attr_name (#eq? @attr_name "class") (quoted_attribute_value) @attr_value)))이렇게 element 노드에서 정직하게 타고 내려오는 쿼리를 작성한다면 마치 길 안내를 받듯이 하위 노드에서 상위 노드로 올라갈 수 있다. 하지만 여러 번 시도해본 결과, 이게 참 바보 같은 시도였다는 것을 느꼈는데 왜냐하면 모든 경우의 수를 다룰 수 있는 쿼리를 작성하는 것은 거의 불가능에 가깝기 때문이다. 예를 들어서 여러 번 중첩된, 아주 복잡한 구조의 리액트 컴포넌트가 있다고 하면, 그 구조를 예측하고 클래스 속성이 담긴 노드를 캡처하는 쿼리를 작성하는 일은 매우 힘들다. 그리고 오류에도 취약하다. 만약 중첩된 노드를 위한 와일드카드 노드가 있었더라면 가능했을 수도 있지만 아쉽게도 그런 건 찾을 수 없었다.
옵션 2: 캡처한 노드의 범위를 저장하고 비교하기
사실 해결책은 간단하다. iter_captures에 전달하는 탐색 범위를 늘리면 된다. 나는 바보같이 길고 복잡한 쿼리를 완벽하게 작성하는 데 정신이 팔려서 이 방법을 생각해내는 데 오래 걸렸다. 또 iter_captures 함수에 시작과 끝줄을 명시하지 않으면 자동으로 그 값들을 건네받은 노드에서 추출하는데, 나는 전체 문서에서 탐색한다고 오해를 하는 바람에 한 줄 탐색에 계속 집착을 했었다. 그럴 필요가 없었는데.
이제 간단하게 iter_captures가 반환하는 가장 첫 번째 노드가 클래스 속성을 가졌는지 확인하고 그 결과에 따라 맞는 동작을 수행할 수 있다. 시작 태그와 클래스 속성의 위치 정보를 변수에 저장하고 클래스 속성 노드의 범위가 시작 태그 노드 범위 안에 포함되어 있다면 공백을 넣고 없다면 새로운 속성을 추가하면 된다.
그리고 nvim_feedkeys를 쓰는 대신에 vim.api.nvim_buf_get_lines와 vim.api.nvim_buf_set_lines를 사용해서 여러 줄의 걸친 요소도 처리할 수 있도록 바꿔준다.
마지막으로 iter_captures가 반환하는 노드를 모두 살펴볼 필요 없이, 첫 번째 노드에 원하는 정보가 다 있기 때문에 반복문 대신 함수를 직접 호출한다.
-- `iter_captures` 함수를 직접 호출한다
-- get_tag_query와 get_attr_query는 내가 미리 만든 유틸 함수다
local get_tag = queries.get_tag_query(lang):iter_captures(node, bufnr)
local get_value = queries.get_attr_query(lang):iter_captures(
node,
bufnr
)노드를 리턴하는 get_tag와 get_value 함수를 만들고 다음과 같이 사용한다:
-- id 값은 사용하지 않는다
local _, tag = get_tag()
local _, class = get_value()
local _, value = get_value()만약 class 노드가 nil이라면 클래스 속성이 아예 없다는 뜻이므로 새로 추가해주어야 한다.
커서 위의 요소보다 하위 요소의 클래스 속성을 캡처하는 경우도 있다. 이때는 리턴된 노드가 가장 바깥 요소(커서 위의 요소)에서 온 값인지 확인하기 위해 위치정보를 비교한다. 위에서 말했듯이 태그 노드의 범위가 클래스 속성 노드의 범위를 포함한다면 가장 바깥 요소에서 온 값이라고 생각할 수 있다.
-- 캡처된 노드가 가장 바깥 요소에서 온 게 아니라면,
-- 현재 요소에 클래스 속성이 없다는 뜻이다
-- 따라서 새로 추가해야 한다.
if
-- 클래스 속성과 시작 태그의 행(row number)을 비교한다
(
ranges["value"].start_row < ranges["tag"].start_row
or ranges["value"].end_row > ranges["tag"].end_row
)
-- 만약 같은 줄에 위치한다면 열(column number)을 비교한다
or (
utils.is_same_line(ranges["value"].end_row, ranges["tag"].end_row)
and ranges["value"].start_col > ranges["tag"].end_col
)
then
-- 새로운 클래스 속성을 추가한다
-- 요소가 두 줄 이상일 경우에 대비하여
-- nvim_feedkeys 대신 get/set_lines 함수를 사용한다
local replace_line = function(line, start_col, end_col, insert_str)
local new_line = line:sub(0, start_col) .. insert_str .. line:sub(end_col + 1)
return new_line
end
local lines = vim.api.nvim_buf_get_lines(bufnr, ranges["tag_name"].start_row, ranges["tag_name"].end_row + 1, false)
local new_line = replace_line(lines[1], ranges["tag_name"].start_col, ranges["tag_name"].end_col , [[class=""]])
vim.api.nvim_buf_set_lines(bufnr, ranges["tag_name"].start_row, ranges["tag_name"].end_row + 1, false, { new_line })
vim.api.nvim_win_set_cursor(0, { ranges["tag_name"].end_row + 1, ranges["tag_name"].end_col })
vim.cmd("startinsert")
end그리고 만약 value 노드가 nil이 아니라면 정의된 클래스 속성이 있고 값이 이미 들어있다는 뜻이 된다. 이 경우에는 위와 비슷한 방법으로 공백만 추가해주면 된다. value 노드의 값이 비어있는 경우라면 (class=""인 경우) 공백을 추가로 넣을 필요가 없다. 이때는 커서만 옮겨준다.
-- 캡처된 노드에 nil이 아닌 경우
-- 공백 추가
if value ~= nil then
-- nil은 아니지만 비어있는 문자열이라면
-- 공백 추가 필요 없음
local has_value = string.len(utils.get_node_text(value)) > no_content_len
local inject_str = has_value and " " or ""
ranges["value"].end_col = has_value and ranges["value"].end_col
or ranges["value"].end_col - 1
local replace_line = function(line, start_col, end_col, insert_str)
local new_line = line:sub(0, start_col) .. insert_str .. line:sub(end_col + 1)
return new_line
end
local lines = vim.api.nvim_buf_get_lines(bufnr, ranges["value"].start_row, ranges["value"].end_row + 1, false)
local new_line = replace_line(lines[1], ranges["value"].start_col, ranges["value"].end_col , "")
vim.api.nvim_buf_set_lines(bufnr, ranges["value"].start_row, ranges["value"].end_row + 1, false, { new_line })
vim.api.nvim_win_set_cursor(0, { ranges["value"].end_row, ranges["value"].end_col })
vim.cmd("startinsert")
end마치며
이 글은 어쩌면 제목과는 다르게 플러그인을 만드는 데 그다지 도움이 되는 글이 아닐지도 모른다. 내가 겪은 경험을 그대로 전달하려다 보니 조금 길어진 것도 사실이다. 하지만 이 글이 읽는 사람의 상상력을 자극하고 더욱 기발한 플러그인 같은 결과로 이어지면 좋겠다.
글을 마치기 전 꼭 해야 할 말 한 가지는 글이 너무 지루하고 길어질까 봐 많은 부분을 빼놓고 이야기했다는 점이다. 혹시 궁금하다면 내가 빼놓은 것들은 다음과 같다:
JSX를 위한 쿼리- 클래스 속성 삭제 함수
- 템플릿 리터럴(template literals) 다루는 법
astro나markdown에서 동작하게 하는 법
좀 더 자세한 코드가 궁금할 사람들을 위해 코드를 정리해서 classy.nvim이라는 이름의 네오빔 플러그인으로 만들어봤다. 더 자세한 문서와 설치 방법은 아래의 링크를 통해서 확인할 수 있다.
혹시 궁금한 점이 있거나 대화를 나누고 싶다면 jhcha.app 을 통해 말 걸어주셨으면 좋겠다 :)
💡 마지막 팁 (또는 홍보)
얼마 전에 TailwindCSS의 클래스 이름을 CSS 코드로 변환시켜주는
cmp-tw2css
라는
플러그인을 만들었다. HTML 문서 안에서 classy.nvim과 cmp-tw2css의
궁합이 정말 좋다. 궁금한 사람은 꼭 확인해봤으면 좋겠다.