The power of tree-sitter
Intro
I’ve been spending more time on twitter than ever mainly to follow the trend in the dev world and to be inspired by others.
Last week, I encountered this tweet:
and thought it is a good (and simple) demonstration of what Neovim with built-in treesitter is capable of. When writing HTML documents, I get tired of editing class attributes very soon, and that’s exactly what
justinrassier
is trying to solve here. I thought it would be cool to have it in my init.lua, so I cloned it with some little tweaks and this post is going to explain how I did. But before I dive deeper into that, let’s pinpoint the problems first!
Problem
- Moving cursor to add or edit a classname is tiresome. The more classnames you have, the more keystrokes you need.
- Adding a new class attribute is even more annoying. You have to move your cursor and type
class="...". If you’re using JSX / TSX then you have to typeclassName="...". It’s such a hassle! - Removing a class attribute from a tag can be boring, too. Imagine you are at the bottom of your document and need to remove the class attribute from the
<html>opening tag. Yeah, you can doggto move your cursor to the top but I need a more convenient way.
Solution
- Let’s make a utility function that automatically puts the cursor to the end of the existing class attribute (as shown in the tweet above). The function should behave the same regardless of your cursor position as long as it is within the same context. For example, calling the function from the opening tag and the closing tag should give the same result.
- If there is no existing class attribute, then the function should add a new
class=""for you. It should be able to addclassName=""if the parsed language is JSX or TSX. - The second utility function should be able to remove the whole class attribute from the tag.
I have my solutions proposed, and it’s time to do some Tree-sitter magic✨.
What is Tree-sitter?
Tree-sitter(or treesitter) is a parser generator tool and an incremental parsing library. It is important to note that it supports incremental parsing because it means that treesitter does not need to parse the whole document when something has changed, so it’s faster than the other traditional parsers. It’s good to understand how treesitter works but it’s totally fine to use it without mastering the tool thanks to Neovim’s built-in treesitter API.
Starting from version 0.5, Neovim has native treesitter support with some helpful built-in functions, and it is what makes Neovim so powerful compared to Vim. For example, syntax highlighting and indentation used to be the two most annoying things to set up, but now with Tree-sitter, they work like a charm even for languages with more complicated structures. This is particularly good news for those who write front-end codes in Vim environment as many cutting-edge frameworks are often mixtures of JavaScript / JSX / TypeScript / HTML / CSS.
If you’re interested to know more about treesitter, I recommend starting from the official website .
How to use Tree-sitter in Neovim
To install language parsers, you first need a plugin called nvim-treesitter . This plugin does not come with Neovim but it is a must-have. You can think it as a parser manager for Neovim and it provides some useful utility functions as well. Another helpful plugin is nvim-treesitter/playground . It is a playground where you can write treesitter queries and see the result instantly, so I recommend using it too.
Once you downloaded the plugins and the parsers, it’s time to write some queries.
Tree-sitter Query 101
As soon as you enable the treesitter, it generates a syntax tree that maps directly to the structure of your code. By writing queries you can easily access and manipuate the nodes in the syntax tree and do magical things with them.
To access and capture a node you write the name of the node inside the parentheses and capture it by writing a @ symbol followed by a unique name.
((node) @my_node)To traverse into the syntax tree and access the nested nodes you put another node enclosed by parentheses before the closing parenthesis of its parent node.
((node (nested_node) @my_nested_node))There are two more syntaxes that I found useful while writing queries: wildcard node and alternation.
Wildcard node (_) can be used when you want to target any node at the desired position. This is similar to . in regular expression and can be used like this:
(node (_) @nested_node)
# or
(node (_ (child_node)))You can also specify possible patterns using the alternation syntax. It’s written as a pair bracket ([]) containing a list of patterns.
(node [(this_node) @this (that_node) @that])There are some more tips and tricks but I don’t want to make this post boring by throwing all the syntax you could use. So now I’ll show you what a parser tree could look like. Don’t worry, I’ll make sure I share everything I know in this post. Just keep reading!
(Btw, if you need a better explanation for the query syntax, check out the documentation )
HTML syntax tree
Using the nvim-treesitter/playground plugin, you can open up the playround and check the visual representation of the syntax tree by typing :TSPlaygroundToggle in command mode. If this gives you an error, make sure you have the parser downloaded in your Neovim.
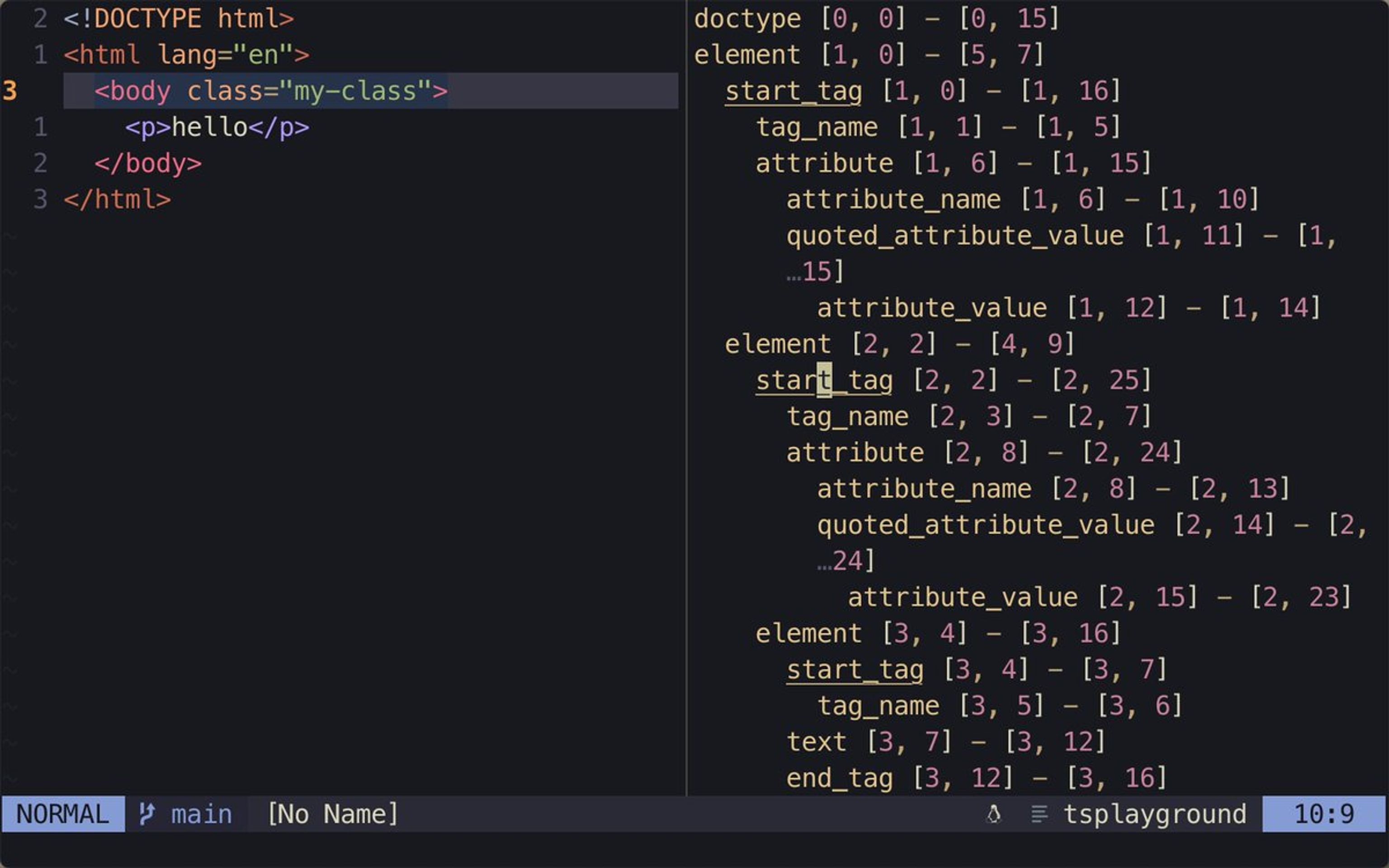
Imagine you have a small HTML document:
<!DOCTYPE html>
<html lang="en">
<body class="my-class">
<p>hello</p>
</body>
</html>which would be visualized as:
doctype [0, 0] - [0, 15]
element [1, 0] - [5, 7]
start_tag [1, 0] - [1, 16]
tag_name [1, 1] - [1, 5]
attribute [1, 6] - [1, 15]
attribute_name [1, 6] - [1, 10]
quoted_attribute_value [1, 11] - [1, 15]
attribute_value [1, 12] - [1, 14]
element [2, 2] - [4, 9]
start_tag [2, 2] - [2, 25]
tag_name [2, 3] - [2, 7]
attribute [2, 8] - [2, 24]
attribute_name [2, 8] - [2, 13]
quoted_attribute_value [2, 14] - [2, 24]
attribute_value [2, 15] - [2, 23]
element [3, 4] - [3, 16]
start_tag [3, 4] - [3, 7]
tag_name [3, 5] - [3, 6]
text [3, 7] - [3, 12]
end_tag [3, 12] - [3, 16]
tag_name [3, 14] - [3, 15]
end_tag [4, 2] - [4, 9]
tag_name [4, 4] - [4, 8]
end_tag [5, 0] - [5, 7]
tag_name [5, 2] - [5, 6]I’m interested in the element node and its nested children. The start_tag is the node for opening tags in HTML, and the tag_name and attribute nodes have some useful information that I might need later.
In treesitter playground, the corresponding element gets highlighted as you move your cursor around. Pressing I will show you the language each node is associated with and pressing o will open up the scratchpad where you can test your queries.
Writing queries to capture class attribute value
There are three cases to handle.
- An element without any class attribute
- An element that has a class attribute that does not contain any value
- An element with a class attribute that has some values
<p>case 1</p>
<p class="">case 2</p>
<p class="my-class ...">case 3</p>For the first case, I can simply capture the attribute_name node and see if it is empty or not. In this case, I would also want to capture the tag_name node as a reference so that I can add a new class attribute next to the tag_name node’s position.
((attribute_name) @attr_name)# there are two types of tags in HTML
([( start_tag ) ( self_closing_tag )] @tag)For the other two cases, I need to check the quoted_attribute_value node for its value. However, I don’t really need to get values from other types of attributes like src or href because I only care about the class attribute. How can I write a query that matches only with the class attribute?
Predicates
To match a certain type of node with a condition, you can use the treesitter’s predicate syntax.
((attribute_name) @attr_name (#eq? @attr_name "class") (quoted_attribute_value) @attr_value)I used the equality predicate to check if the attribute name matches to the class string, and this way I can ignore all other attributes.
Neovim supports other types of predicates that you might find useful. Please check out the documentation for more information.
Iterating over captured nodes
Now that you have written the query, you can iterate over the captured nodes and do whatever you need to do. The first step is to parse the query by passing the query to Neovim’s parse_query function. It also requires you to pass the lang parameter, and this can be inferred from the document’s filetype.
local filetype = vim.api.nvim_buf_get_option(0, "ft")
local lang = require("nvim-treesitter.parsers").ft_to_lang(filetype)
local query_text = [[ ... ]] -- your query
local query = vim.treesitter.query.parse_query(lang, query_text)💡 quick tip
nvim-treesitter.parsers module provides a useful function called
ft_to_lang which can handle edge cases you might encounter when parsing
JSX / TSX.
This will return a query object that you can use when iterate a node using iter_captures method. iter_captures takes four parameters: a node you want to search through, a buffer number, and start / end line numbers for the search. It will return the id, captured node as a table, and a metadata table.
-- for-loop pattern
for id, capture, metadata in query:iter_captures() do
-- ...
end💡 quick tip
The most convenient way to see the content of the captured node is to print
it out. However, the print function does not work with tables. The trick
is to use print(vim.inspect(table)) or vim.pretty_print(table).
Everything looks good, right? You only need a starting node that will be handed over to the iter_captures function. Which node should I use? Obviously, I should start from the node under my cursor, so let me show you how it works.
There is a built-in function called get_node_at_cursor in vim.treesitter module, but this function only returns the name of a node as a string, and not as a tsnode instance. Luckily, nvim-treesitter.ts_utils provides a better one with the same name.
local ts_utils = require("nvim-treesitter.ts_utils")
local node = ts_utils.get_node_at_cursor()This is great…? Well, what if your cursor was not on the element node? It would give you a child or grandchild node of the element node, and that’s not what we want. We need to recursively climb up the syntax tree and find the element node at the nearest position.
while node:type() ~= "element" do
-- handling the edge cases like `doctype` node
if node:parent() == nil then
return
end
node = node:parent()
endWe have ensured that our node is an element node, and we can pass this to the iter_captures we saw earlier.
-- get cursor position
local cursor = vim.api.nvim_win_get_cursor(0)
local cursor_row, cursor_col = unpack(cursor)
for id, capture, metadata in query:iter_captures(node, bufnr, cursor_row - 1, cursor_row) do
-- get range information from captured node
local capture_start_row, capture_start_col, capture_end_row, capture_end_col = capture:range()
local name = query.captures[id]
if name == "attr_value" then
vim.api.nvim_win_set_cursor(0, { capture_end_row + 1, capture_end_col })
-- change to insert mode
vim.cmd("startinsert")
-- add a space at the end
vim.api.nvim_feedkeys(" ", "n", false)
end
endHere, I’m looking for attr_value nodes and if it does match, I put the cursor using the row and column information, start the insert mode and manually add a space(" ").
Handling multi-line element case
The solution above worked well until I tested on an element that has more than one line. This is problematic considering that multi-line element is common in JSX. It would not work as expected because we are searching only on the line where the cursor is, and because there is no appropriate row number to refer to when setting the cursor.
For the same reasons, calling the function when the cursor is not on the opening tag will not trigger the right behavior.
Also, I don’t like the idea of using nvim_feedkeys because it feels a little hacky to me.
So how do we solve this problem?
Option 1: Write a perfect query
The first option is to write a perfect query that considers every possible combination of an element node. Once you have that perfect query, the parser would be able to percolate up the syntax tree even from the closing tag. This is probably easier to understand with some examples:
;; get @tag_name
(element [(start_tag (tag_name) @tag_name) (self_closing_tag (tag_name) @tag_name)])
;; get class attribute value
(element (_ (attribute (attribute_name) @attr_name (#eq? @attr_name "class") (quoted_attribute_value) @attr_value)))This was one of many attempts to capture the quoted_attribute_value using the wildcard node and alternation syntax. By writing queries that start from the element node like this, you are providing the context to the parser, and it can then reach up to the parent node even when you pass the single line range to the iter_captures function.
However, this option is error-prone since it is impossible to write a perfect query. I mean, imagine you have a complicated, deeply nested, React component that contains interpolation syntax. How would you write a query to target all possible cases? It might have been possible if there were a wildcard symbol for nested nodes but, sadly, we do not have that.
Option 2: Save the node range and compare
This was a simple solution that I had a hard time coming up with because I was obsessed with the idea of solving it by writing long queries. After I found out that it’s not possible to handle all the cases in JSX, I realized I can simply check whether the first captured node has attribute values. 🤦 Also, there was no need to be concerned with passing a larger range to the iter_captures function because when the start and end row values are omitted, iter_captures extracts those values from the given node (the element node for our case).
For my final solution, I used vim.api.nvim_buf_get_lines and vim.api.nvim_buf_set_lines to replace multiple lines to handle multi-line elements, and rather than using the for loop, I called iter_captures directly because I don’t need to go over all the captured nodes.
-- Call the iterator directly instead of looping over
-- get_tag_query and get_attr_query are my own util functions
local get_tag = queries.get_tag_query(lang):iter_captures(node, bufnr)
local get_value = queries.get_attr_query(lang):iter_captures(
node,
bufnr
)I declared two new functions that return the first result of the iterator. They can be used like this:
-- ids are ignored
local _, tag = get_tag()
local _, class = get_value()
local _, value = get_value()If the class node is nil, it means that there is no class attribute at all. So I need to add a new class attribute. There is one more case to handle. With this method, I cannot guarantee that the returned values are actually from the outermost element.
So I need to manually check if the row number of the attribute value matches the row number of the tag node. And also compared the column numbers.
-- if the captured node is not from the outermost tag,
-- it means that the element has no class attribute,
-- so add a new one
if
-- compare the row numbers of value and opening tag
(
ranges["value"].start_row < ranges["tag"].start_row
or ranges["value"].end_row > ranges["tag"].end_row
)
-- or if the two tags are on the same line, compare the column numbers
or (
utils.is_same_line(ranges["value"].end_row, ranges["tag"].end_row)
and ranges["value"].start_col > ranges["tag"].end_col
)
then
-- the captured node is not from the outermost tag
-- so add a new class attribute
-- it can be a multi-line element so use get/set_lines
-- instead of nvim_feedkeys
local replace_line = function(line, start_col, end_col, insert_str)
local new_line = line:sub(0, start_col) .. insert_str .. line:sub(end_col + 1)
return new_line
end
local lines = vim.api.nvim_buf_get_lines(bufnr, ranges["tag_name"].start_row, ranges["tag_name"].end_row + 1, false)
local new_line = replace_line(lines[1], ranges["tag_name"].start_col, ranges["tag_name"].end_col , [[class=""]])
vim.api.nvim_buf_set_lines(bufnr, ranges["tag_name"].start_row, ranges["tag_name"].end_row + 1, false, { new_line })
vim.api.nvim_win_set_cursor(0, { ranges["tag_name"].end_row + 1, ranges["tag_name"].end_col })
vim.cmd("startinsert")
endLastly, if the value is not nil, then I simply add a new space and put the cursor at the end.
If the value node only contains a set of quotation marks (empty string), there’s no need to add a space. Just put the cursor between the quotation marks.
-- if the captured node has some values,
-- add a space at the end
if value ~= nil then
-- if the attribute value is just an empty string (""),
-- no need to add a space
local has_value = string.len(utils.get_node_text(value)) > no_content_len
local inject_str = has_value and " " or ""
ranges["value"].end_col = has_value and ranges["value"].end_col
or ranges["value"].end_col - 1
local replace_line = function(line, start_col, end_col, insert_str)
local new_line = line:sub(0, start_col) .. insert_str .. line:sub(end_col + 1)
return new_line
end
local lines = vim.api.nvim_buf_get_lines(bufnr, ranges["value"].start_row, ranges["value"].end_row + 1, false)
local new_line = replace_line(lines[1], ranges["value"].start_col, ranges["value"].end_col , "")
vim.api.nvim_buf_set_lines(bufnr, ranges["value"].start_row, ranges["value"].end_row + 1, false, { new_line })
vim.api.nvim_win_set_cursor(0, { ranges["value"].end_row, ranges["value"].end_col })
vim.cmd("startinsert")
endOutro
This post demonstrates only a little portion of what you could do with treesitter in Neovim. As always, imagination is the only limit to what we can do. I hope you had fun reading this and it inspires you to build cooler things with treesitter. I enjoy writing small Neovim plugins that enhance developer experience like this!
One thing I should say is that I excluded many chunks from the actual source code to make this post concise (I hope). I didn’t want to explain every single piece of code but wanted to walk you through my thought process and share what I learned.
If you’re interested, here’s a list of things I left out:
- Queries for JSX
- Remove function
- How to deal with the template strings
- How to handle
astroandmarkdown
I eventually made this as a Neovim plugin called classy.nvim so that you can install and see how convenient it is. It has more detailed documentation and you can even pass an option to decide whether to use single quotation marks instead of double.
If you have any questions, feel free to dm me on jhcha.app at any time :)
💡 one last tip (or self-promotion)
I have anoter plugin called
cmp-tw2css
which converts
TailwindCSS classes into pure css codes. Using cmp-tw2css with classy.nvim
in an HTML document is a perfect match, so check that out too.